














Orfium for Broadcasters
Streamline management of your music cue sheets and production metadata with Soundmouse and Silvermouse. Find and license content with ease with MusicBox.
Get in touch

At Orfium, our mission is to unlock the full potential of content. That’s why we created Sync-Tracker, a groundbreaking solution for managing licensed and unlicensed music on YouTube. Whether you’re a music production company, a content creator, or simply someone uploading content on YouTube, Sync-Tracker is designed to cater to your needs. With Sync-Tracker, you can easily handle licensed and unlicensed music, while providing music production companies a platform to sell licenses to content creators. Additionally, users can enforce their licenses through YouTube’s Content ID, making Sync-Tracker a powerful tool for protecting your rights and ensuring compliance.
SyncTracker is a powerful licensing software that keeps a close eye on YouTube claims generated after the upload of a video, regardless of its privacy settings. Leveraging advanced audio and melody-matching algorithms, SyncTracker analyzes the content owner’s extensive catalog of assets to identify any potential matches. For more information on YouTube’s claims and policies, please refer to the detailed documentation available here.
Cracking the Code: Insights into Efficient Claim Tracking 🧑💻
To track claims efficiently, our technical approach involves leveraging the ClaimSearch.list API call. This API call allows us to retrieve claims based on specific statuses in a paginated manner. For instance, if there are 100 claims on YouTube, the initial request may only fetch 20-30 claims, accompanied by a nextPageToken. To access claims from subsequent pages, additional requests with the nextPageToken are necessary. This iterative process of making sequential ClaimSearch.list API calls enables us to gather all the claims seamlessly. Below, you’ll find a high-level diagram outlining the flow of tracking and processing claims, reflecting our recent advancements in this area.

What’s the daily maximum number of claims we can track from YouTube content ID?
Determining the maximum number of claims we can track from YouTube’s Content ID per day involves calculating the theoretical upper limit based on response time and claim quantity. Assuming an average of 0.5 seconds for each request/response and approximately 20 claims obtained per call, we can estimate a capacity of around 3.5 million claims per day. Previously, we faced limitations in approaching this limit due to the sequential processing of each claim batch.
The Chronicle of the Ages: Unveiling the History of Traffic Increase⏳
The solution we implemented until the end of 2022 served us flawlessly, catering to the manageable volume of claims we handled at the time. By the close of 2022, Orfium’s YouTube snapshot encompassed approximately 250,000 assets, with YouTube generating an average of around 30,000 claims per day for these assets.
However, the landscape changed in early 2023, when Orfium secured significant contracts with large Music Production Companies (MPCs). This development projected a substantial 5.5x increase in the Content ID (CiD) size, resulting in a total of 1.4 million assets. With this expansion, the claim traffic was also expected to grow. Estimating the precise increase in claim traffic proved challenging as it does not have a linear relationship with the number of assets. The quantity of claims generated depends on the popularity of each song, not just the sheer number of songs. We encountered scenarios where a vast catalog generated regular traffic due to the songs’ lack of popularity and vice versa. Consequently, we anticipated a claim traffic growth of at least 3-4x. However, our old system could only handle a maximum increase of 2x traffic 💣, prompting the need for upgrades and improvements.

Success Blueprint: Strategizing for Achievement and Risk Mitigation 🚧
As our development team identified the impending performance bottleneck, we immediately recognized the need for proactive measures to prevent system strain and safeguard our new contracts. The urgency of the situation was acknowledged by the product Business Unit (BU), prompting swift action planning.
We initiated a series of brainstorming meetings to explore potential short-term and long-term solutions. With the adage “prevention is better than cure” guiding our approach, we devised a backlog of mitigation strategies to address the increased risk until the customer deals were officially signed. We were given a demanding timeframe of 4-6 weeks to complete all activities, including brainstorming meetings, analysis, design, implementation, testing, production delivery, and monitoring. The challenge lay in the uncertainty surrounding the effectiveness of the chosen solution.
After several productive brainstorming sessions, we compiled a comprehensive list of potential alternatives. These ranged from pure engineering decisions to YouTube-side configuration ideas, ensuring that every possible avenue was explored to ensure the safety and security of the new contracts.
Unleashing the Power of Solutions: Overcoming Traffic Challenges and Streamlining Claims Tracking 🧩
With the primary goal of reducing the time spent in claims tracking, we embarked on a journey to introduce innovative solutions. One such solution involved the implementation of a new metric in Datadog, designed to detect any missing claims. This introduced a proactive approach to monitor if any claims were not being tracked by our application and enabled us to identify and address related issues promptly. By leveraging this powerful tool, we gained valuable insights into potential issues such as increased traffic and timeouts, empowering us to take swift action and maintain optimal performance.
The solutions we discussed to enhance our claims tracking process included:
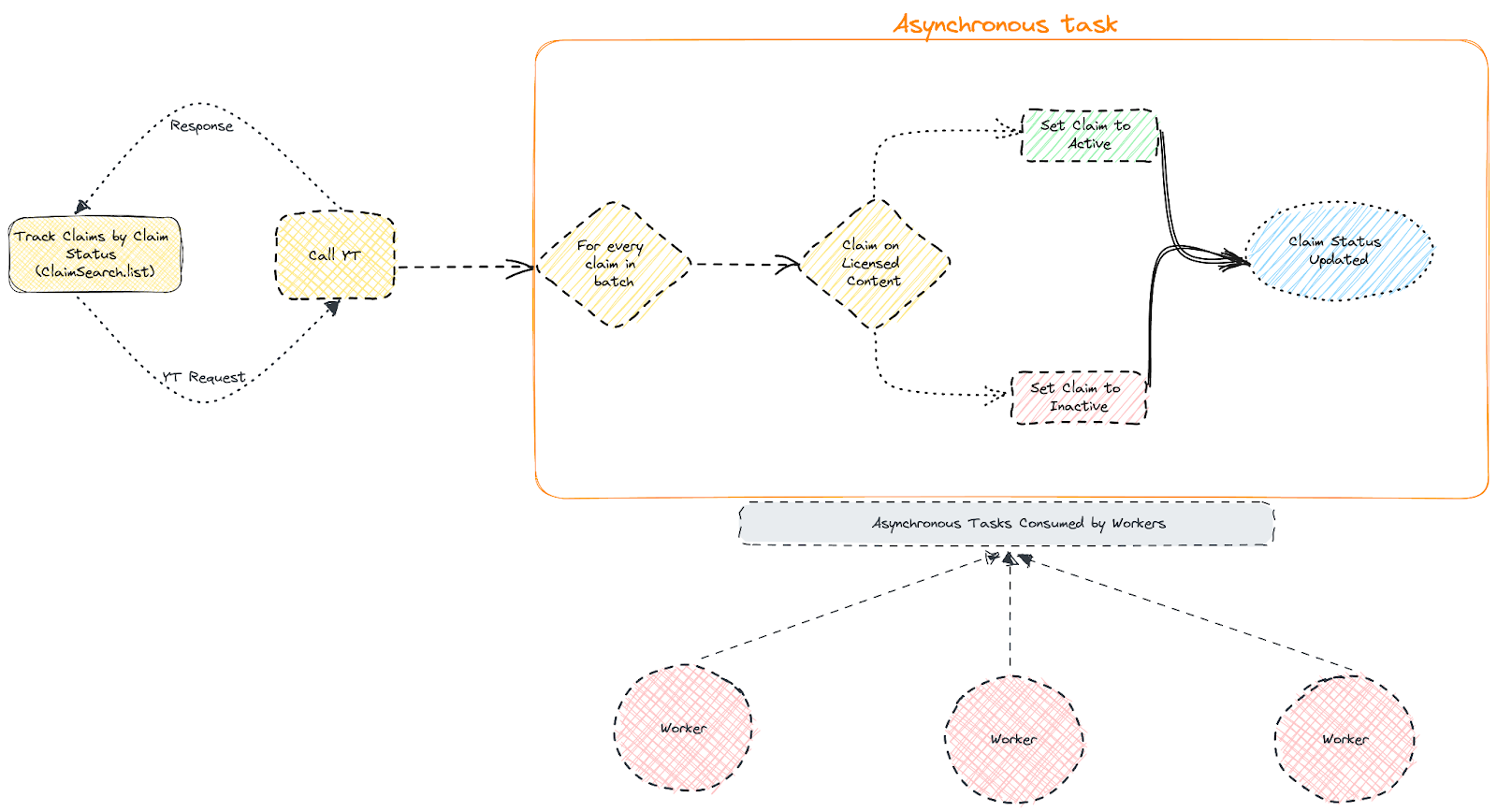
Solving the Puzzle: Addressing Production System Issues through Troubleshooting 📚
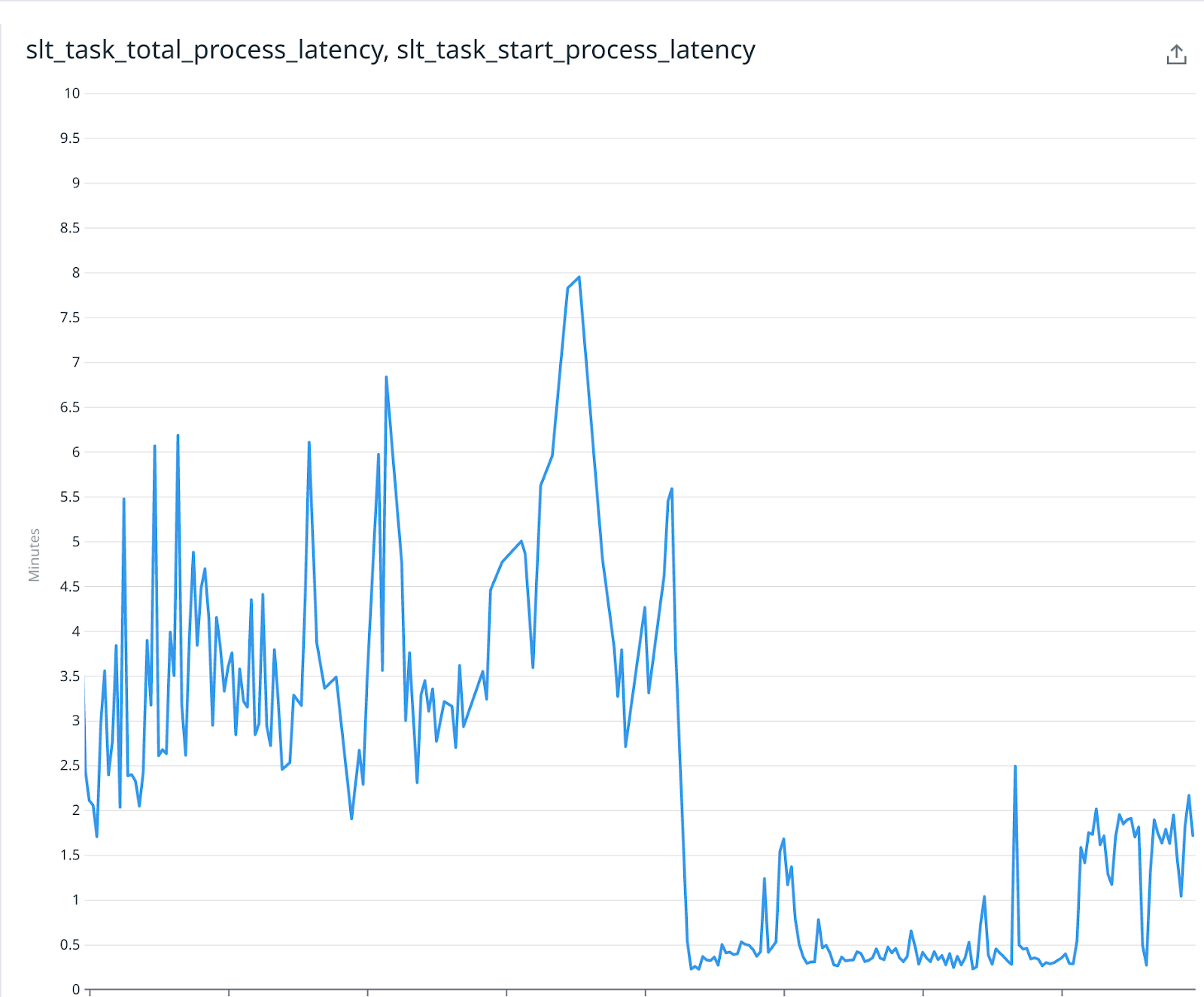
In the world of production systems, Murphy’s Law always lurks, ready to present unexpected challenges. After deploying the async implementation, everything seemed to be working smoothly for approximately 8 hours. However, we soon encountered a significant increase in the processing time of each request, disrupting the expected flow. Fortunately, thanks to our vigilant monitoring through Datadog metrics, we were able to detect the issue before it caused any service disruptions.

In light of the async solution implementation and concurrent query execution, our workflow encountered a significant setback due to time-intensive database queries for each monitored claim. This resulted in multiple query locks and idle worker processes. To tackle this problem, we strategically tackled the situation by identifying and eliminating unnecessary indexes from the license table. Additionally, we meticulously benchmarked the pertinent license-matching queries. Remarkably, we discovered that the queries filtered by video_id were the slowest.

In order to effectively address this performance bottleneck, we took proactive measures by creating a brand-new index specifically designed for license-matching queries. This optimization led to a remarkable reduction in overall processing time, with the median duration plummeting from 4-5 minutes to an impressive 1 minute. This represents a substantial decrease of 400-500%, greatly enhancing efficiency and productivity.
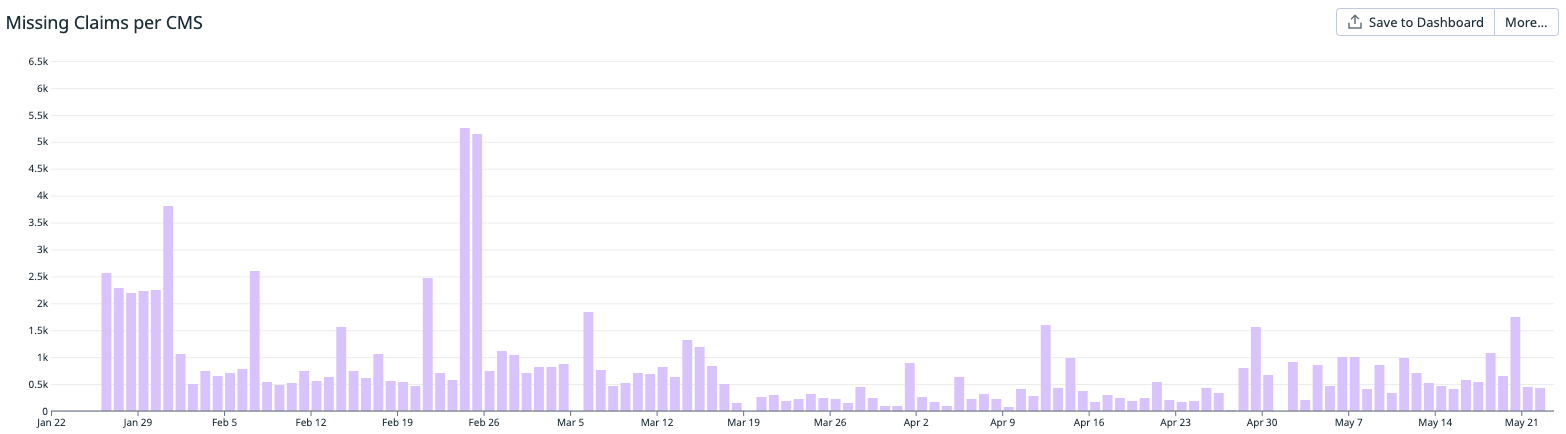
Closing the Chapter: Onboarding Outcomes Explored 🏁
Following the successful onboarding of new customers, we witnessed a remarkable surge in claim traffic, experiencing an eightfold increase from 50,000 to nearly 400,000.

Presently, the SyncTracker application maintains exceptional stability and seamlessly manages the influx of claim traffic. Based on our careful projections, we have determined that our system is fully capable of accommodating claim traffic up to the maximum threshold allowed by the YouTube API, which amounts to approximately 3 million claims per day. Furthermore, we are proud to report a remarkable decrease of approximately 700% in the total number of missing claims. This figure has significantly dropped from 1,500 down to less than 100, underscoring the effectiveness and efficiency of our platform.
Considering all factors, there are additional minor optimizations that are currently being developed and are expected to yield an average time-saving of 15%-20%. These enhancements are still in the pipeline and have not yet been implemented in the production environment. It is important to note that despite our current success, this milestone does not signify the end of our journey. We remain committed to continuously improving our processes and striving for further advancements.
Abbreviations 🤏
MPC – Music Production Companies
CiD – YT Content ID
CMS – Content Management System -used interchangeably with CiD-
YT – YouTube
ST – SyncTracker
BU – Business Unit
E2E – End to End





This week, we announced our partnership with PRS for Music, the leading music rights organization. This collaboration is set to revolutionize the music industry in Africa as PRS expands its licensing coverage to music users based in Africa supported by Orfium’s licensing and technology infrastructure. This will provide access to tens of millions of works, including many of the most successful songs and compositions of today and the last century. The thriving African music industry is set to experience a boost in innovation, efficiency, and growth through this collaboration, which will ultimately benefit the talented songwriters, composers, and publishers across the continent as well as the music users.
Orfium will be licensing the PRS repertoire and providing the technology infrastructure needed to efficiently serve the African music market. The partnership marks a significant milestone, paving the way towards equitable remuneration for talented songwriters, composers, and publishers across Africa for their creative work.
This partnership is expected to bring about significant benefits including increased speed to market for music creators, improved music discovery, as well as cost efficiencies.
An exciting aspect of this partnership is the expansion of PRS for Music’s Major Live Concert Service, the royalty collection service for large concerts, which will now be available for events held across Africa. This is a significant step in expanding the global reach of PRS for Music’s services and supporting music creators in Africa.
In addition to PRS’s existing agreement with SAMRO, the collecting society based in South Africa, the partnership with Orfium will provide a framework for PRS members to be paid when their works are used in some of the world’s fastest-growing music markets. This is a crucial development that ensures songwriters, composers, and publishers are fairly compensated for their music across the African continent.
“We’re incredibly excited to partner with PRS for Music. Orfium exists to support and improve the global entertainment ecosystem so that creators everywhere can be paid fairly for their work. Over the last three years, we have invested heavily in building a state-of-the-art rights management platform to support our partners in the licensing and remuneration of music rights in the entertainment industry. Orfium looks forward to working with PRS as their trusted partner to support this incredible region and contributing to Africa’s future as a high-growth music market.” Rob Wells, CEO, Orfium
Stay tuned to the latest news and updates from Orfium. Subscribe to our newsletter below.

As described in a previous blog post from ORFIUM’s Business Intelligence team, the set of tools and software used varied as time progressed. A shorter list of software was used when the team was two people strong, a much longer and more sophisticated one is being currently used.
As described previously, the two people in the BI team were handling multiple types of requests from various customers from within the company and from ORFIUM’s customers. For the most part, they were dealing with Data Visualization, as well as a small part of data engineering and some data analysis.
Since the team was just the two of them, tasks were more or less divided in engineering and analysis vs visualization. It is simple to guess that in order to combine data from Amazon Athena and Google Spreadsheets or ad-hoc csv’s, a lot of scripting was used in Python. Data were retrieved from these various sources and after some (complex more often than not) transformations and calculations the final deliverables were some csv’s to either send to customers, or load on a Google Sheet. In the latter case a simple pivot table was also bundled in the deliverable in order to jump start any further analysis from the, usually internal, customer.
In other cases where the customer was requesting graphs or a whole dashboard, the BI team was just using Amazon Athena’s SQL editor to run the exploratory analysis, and when the proper dataset for analysis was eventually discovered, we were saving the results to a separate SCHEMA_DATASET in Athena itself. The goal behind that approach was that we could make use of Amazon’s internal integration of their tools, so we provided our solutions into Amazon Quicksight. This seemed at that moment the decision that would provide deliverables in the fastest way, but not the most beautiful or the most scalable.
Quicksight offers a very good integration with Athena due to both being under the Amazon umbrella. To be completely honest, at that point in time the BI Analyst’s working experience was not optimal. From the consumer side, the visuals were efficient but not too beautiful to look at, and from ORFIUM’s perspective a number of full AWS accounts was needed to share our dashboards externally, which created additional cost.
This process slightly changed when we decided to evaluate Tableau as our go-to-solution for the Data Visualization process. One of the two BI members at that time leaned pretty favorably towards Tableau, so they decided to pitch it. Through an adoption proposal for Tableau, which was eventually approved by ORFIUM’s finance department, Tableau came into our quiver. Tableau soon became our main tool of choice for Data Visualization. It allows better and more educated decisions to be made from management, and is able to showcase the value that our company can offer to our current and potential future clients.
This part of BI’s evolution led to the deprecation of both Quicksight and python usage, as pure SQL queries and DML were developed in order to create tables within Athena, and some custom SQL queries were embedded on the Tableau connection with the Data Warehouse. We focused on uploading ad-hoc csv’s or data from GSheets on Athena, and from there the almighty SQL took over.
The team eventually grew larger and more structured, and the company’s data vision shifted towards Data Mesh. Inevitably, we needed a new and extended set of software.
A huge initiative to migrate our whole data warehouse from Amazon Athena to Snowflake started, with BI’s main data sources playing the role of the early adopters. The YouTube reports were the first to be migrated, and shortly after the Billing reports were created in Snowflake. That was it, the road was open and well paved for the Business Intelligence team to start using the vast resources of Snowflake and start building the BI-layer.
A small project of code migration so that we use the proper source and create the same tables that Tableau was expecting from us, turned into a large project of restructuring fully the way we worked. In the past, the python code used for data manipulation and the SQL queries for the creation of the datasets to visualize were stored respectively in local Jupyter notebooks and either within View definitions in Athena or Tableau Data source connections. There was no version control; there was a Github repo but it was mainly used as a code storage for ad-hoc requests, with limited focus on keeping it up to date, or explaining the reasoning of updates. There were no feature branches, and almost all new commits on the main one were adding new ad-hoc files in the root folder and using the default commit message. This situation, despite being a clear pain point of the team’s efficiency, emerged as a huge opportunity to scrap everything, and start working properly.
We set up a working guide for our Analysts: training on usage of git and Github, working with branches, PullRequest templates, commit message guidelines, SQL formatting standards, all deriving from the concept of having an internal Staff Engineer. We started calling the role Staff BI Analyst, and we indeed currently have one person setting the team’s technical direction. We’ll discuss this role further in a future blog post.
At the same time we were exploring options on how to combine tools so that the BI Analysts are able to focus on writing proper and efficient SQL queries, without having to either be fully dependent on Data Engineers for building the infrastructure for data flows, or requiring python knowledge in order to create complex DAGs. dbt and Airflow surfaced from our research and, frankly, the overall hype, so we decided to go with the combination of the two.
Initially the idea was to just use Airflow, where an elegant loop would be written so that the dags folder would be scanned, and using folder structures and naming conventions on sql files, only a SnowflakeOperator would be needed to transform a subfolder in the dags folder to a DAG on the AirflowUI, with each file from the folder would be a SnowflakeOperator task, and the dependencies would be handled by the naming convention of the files. So, practically a folder structure as the one shown to the right would automatically create a Dynamic Dag as shown on the left.

No extra python knowledge needed, no Data Engineers needed, just store the proper files with proper names. A brief experimentation with DAGfactory was also implemented but we soon realized that the airflow should just be used as the orchestrator of the Analytics tasks, and the whole analytics logic should be handled by something else. All this was very soon abandoned when dbt was fully onboarded to our stack.
Anyone who works in the Data and Analytics field must have heard of dbt. And if they haven’t already, they should. This is why there is nothing too innovative to describe about our dbt usage. We started using dbt from early on in its development, having first installed v0.19.1, and with an initial setup period with our Data Engineers, we combined Airflow with dbt-cloud for our production data flows, and core dbt CLI for our local development. Soon after that, and in some of our repos, we started using github actions in order to schedule and automate runs of our Data products.
All of the BI Analysts in our team are now expected to attend all courses from the Learn Analytics Engineering with dbt program offered at dbt Learn regarding its usage. The dbt Analytics Engineering Certification Exam remains optional. However, we are all fluent with using the documentation and the slack community. Generic tests dynamically created through yml, alerts in our instant messaging app in case of any DAG fails, and snapshots are just some of the features we have developed to help the team. As mentioned also above, our Staff BI Analyst plays a leading role in creating this culture of excellence.
There it was. We endorsed the Analytics engineering mindset, we reversed the ETL and implemented ELT, thus finally decoupling the absolute dependency on Data Engineers. It was time to enjoy the fruits of Data Mesh: Data Discovery and Self Service Analytics.
Having more or less implemented almost all of ORFIUM’s Data Products on Snowflake with proper documentation we just needed to proceed to the long awaited data democratization. Two key pillars of democratizing data is to make them discoverable and available for analysis by non-BI Analysts too.
As DataMesh principles dictate, each data product should be discoverable by its potential consumers, so we also needed to find a technical way to make that possible.
We first needed to ensure that data were discoverable. For this, we started testing out some tools for data discovery. Among the ones tested was Select Star Select Star,, which turned out to be our final choice. During the period of trying to find the proper tool for our situation, Select Star was still early in its evolution and development so, after realizing our sincere interest, they invested in building a strong relationship with us, consulting us closely when building their roadmaps, while having a very frequent communication looking to get our feedback as soon as possible. The CEO herself Shinji Kim was attending our weekly call helping us make not just our data discoverable to our users, but the tool itself easily used by our users in order to increase adoption.
Select Star offered most of the features we knew we wanted at that time, and it offered a quite attractive pricing plan which went in line with our ROI expectations.
Now, more than a year after our first implementation, we have almost 100 users active on Select Star, which is a pretty part of the internal Data consumer base within ORFIUM, given that we have a quite large operations department of people who do not need to access data or metadata.
We are looking to make it the primary gateway of our users to our data. All analysis, even thoughts, should start by using Select Star to explore if data exist.
Now, data discovery is one thing, and documentation coverage is another thing. There’s no point in making it easy for everyone to search for table and column names. We need to add metadata on our tables and columns so that the search results of Select Star parse that content too, and provide all available info to seekers. Working in this direction we have established within the Definition of Done of a new table in the production environment a clause that there should be documentation on the table and the columns too. Documentation on the table should include not only technical stuff like primary and foreign keys, level of granularity, expected update frequency etc, but also business information like what is the source for the dataset, as this varies between internal and external producers. Column documentation is expected to include expected values, data types and formats, but also business logic and insight.
The Business Intelligence team uses pre-commit hooks in order to ensure that all produced tables contain descriptions for all the columns and the tables themselves, but we cannot always be sure of what is going on in other Data products. As Data culture ambassadors (more on that on a separate post too), BI has set up a data coverage monitoring dashboard, in order to quantify the Docs coverage of tables produced by other Products, raising alerts when the coverage percentage falls below the pre-agreed threshold.
Tags and Business and Technical owners are also implemented through Select Star, making it seamless for data seekers to ask questions and start discussions on the tables with the most relevant people available to help.
The whole Self-Service Analytics initiative in ORFIUM, as well as Data Governance, will be depicted in their very own blog posts. For now, let’s focus on the tools used.
Having all ORFIUM Data Products accessible on Snowflake and discoverable through Select Star, we were in position to launch the Self-Service Analytics project. A decentralization of data requests from BI was necessary in order to be able to scale, but we could not just tell our non-analysts “the data is there, knock yourself out”.
We had to decide if we wanted Self-Service Analysts to work on Tableau or if we could find a better solution for them. It is interesting to tell the story of how we evaluated the candidate BI tools, as there were quite a few on our list. We do not claim this is the only correct way to do this, but it’s our take, and we must admit that we’re proud of it.
We decided to create a BI Tool Evaluation tool. We had to outline the main pillars on which we would evaluate the candidate tools. We then anonymously voted on the importance of those pillars, averaging the weights and normalizing them. We finally reached a total of 9 pillars and 9 respective weights (summing up to 100%). The pillars list contain connectivity effectiveness, sharing effectiveness, graphing, exporting, among other factors.
These pillars were then analyzed in order to come up with small testing cases, using which we would assess the performance in each pillar, not forgetting to assign weights on these cases too, so that they sum up to 100% within each pillar. Long story short we came up with 80 points to assess each one of the BI tools.
We needed to be as impartial as possible on this, so we assigned two people from the BI team to evaluate all 5 tools involved. Each BI tool was also evaluated by 5 other people from within ORFIUM but outside BI, all of them potential Self-Service Analysts.
Coming up with 3 evaluations for each tool, averaging the scores, and then weighting them with the agreed weights, led us to an amazing Radar Graph.

Though there is a clear winner in almost all pillars, it performed very poorly in the last pillar, which contained Cost per user and Ease of Use/Learning Curve.
We decided to go for the blue line which was Metabase. We found out that it would serve >80% of current needs of Self-Service Analysts, with very low cost, and almost no code at all. In fact we decided (Data Governance had a say on this too) that we would not allow users to be able to write SQL queries on Metabase to create Graphs. We wanted people to go on the Snowflake UI to write SQL, as those people were few and SQL-experienced, as they usually were backend engineers.
We wanted Self Service Analysts to use the query editor, which simulates an adequate amount of SQL features, in order to avoid coding at all. If they got accustomed to using the query builder, then for the 80% of their needs they would have achieved this with no SQL, so the rest of the Self-Service Analysts (the even-less tech savvy) would be inspired to try it out too.
After ~10 months of usage (on the Self-Hosted Open Source version costing zero dollars per user per month, which translates to *calculator clicking * zero dollars total) we have almost 100 Monthly Active Users and over 80 Weekly Active users, and a vibrant community of Self-Service Analysts looking to get more value from the data. The greatest piece of news is that the Self-Service Analysts become more and more sophisticated in their questions. This is solid proof that, within the course of 10 months, they have greatly improved their own Data Analysis skills, and subsequently the effectiveness of their day-to-day tasks.

Within those (on average) 80WAUs, the majority is Product Owners, Business Analysts, Operations Analysts, etc., but there are also around five high level executives, including a member of the BoD.
The BI team and ORFIUM itself have evolved in the past few years. We started from Amazon Athena and Quicksight, and after a part of the journey with python by our side, we have established Snowflake, Airflow, dbt and Tableau as the BI stack, while adding in ORFIUM’s stack Select Star for Data Discovery and Metabase for Self-Sevice Analytics.
More info on these in upcoming posts, but we have more insights to share for the Self-Service Initiative, the Staff BI role, and the Data Culture at ORFIUM.
We are only eager to find out what the future holds for us, but at the moment we feel future-proof.

This is the story of Business Intelligence and Analytics in Orfium, from before there was a single team member or a team itself within the company, to now, where we have a BI organization that scales, Data goals and excited plans for future projects.
Our story is a long one to tell, and one that makes us enthusiastic to tell. We’ll go through the timeline of our journey to the present day, but we fully plan to elaborate on the main points discussed today in their own articles.
We hope you’ll enjoy the ride. Buckle up, here we go!
Before we formally introduced Business Intelligence to Orfium, there were a few BI-adjacent functions at the company. A number of Data Engineers, Operations Managers, and Finance execs created some initial insights with manual data pipelines.
These employees primarily gathered insights on two main parts of the business.
1. Operations Insights – Department and Employee Performance
To get base-level information on the performance of departments and specific employees, a crew of Data Engineers and Operations Managers with basic scripting skills came together, put together a python script, which didn’t lack bugs. The script pulled data from CSV exports from our internal software, as well as exports from AWS S3 that were provided by the DE teams, and connected them to produce a final table. All the transformations were performed within the script. No automation was initially required, as our needs were mostly for data on a monthly basis. The final table would then be loaded on Excel and analyzed through pivot tables and graphs.
This solution provided some useful insights. However, it certainly couldn’t scale along with the organization. A few problems came up along the way which could not be solved by this solution. Not the least of which, our need to have more frequent updates of daily data, to be able to view historical performance, and to join the data with important data from other sources were all reasons why Orfium seeked a bigger, smarter and more scalable solution to BI.
2. Clients Insights
Data Engineers put together a simple dashboard on Amazon QuickSight to give clients insights into the revenues we were generating for them. The data flowed from AWS S3 tables they had created, and they displayed bar charts of revenues over time, with some basic filtering. This dashboard was maintained for a couple of years but ultimately was replaced in March of 2022 with a more comprehensive solution that the BI team provided (spoiler alert: we created a BI team).
In light of some of the issues mentioned above, a small team of BI Analysts was assembled to help with the increasing needs of the Operations team.
The first decision made by the BI Analysts was related to which tools to use for visualization and the ETL process. Nikos Kastrinakis, Director of Business Intelligence, had worked with Tableau previously, so he did a demo and trial with Tableau and ultimately convinced the team to use this as our visualization tool. We also use Tableau Prep as our ETL tool. The company was now storing all relevant data in AWS S3, and the Data Engineers used AWS Athena to create views that transformed the data provided into usable tables that BI could join in Tableau Prep.
During the Tableau trial, the BI team started working on the first dashboard, set to be used by the Operations department, replacing the aforementioned buggy script. We created one Dashboard to rule them all, with information on overall department performance, employee performance, and client performance. This gave users their first taste of the power of a BI team. Our goal was to answer many of their questions in one concise dashboard, complete with historical breakdowns of different types of data, and bring insights that users hadn’t seen before. The Tableau trial ended right before the Dashboard was set to launch. So of course, we purchased our first Tableau licenses for Orfium and onboarded the initial users with the launch of this Dashboard.
It was a huge success! The Operations team was able to phase out their use of the script, stop wasting time monthly to generate reports for themselves, and were exposed to a new way of gaining insights.
Our work with the Operations team didn’t stop there. Over the next many months we continued to work with this data stack. We created further automation to bring daily data to the Operations team so they could manage departments and employees in real-time. But this introduced some new challenges we had to face.
With the introduction of daily estimated data, the frequency of updates and the size of the views made the extracts unusable and obsolete, so we had to face the tradeoff of data freshness VS dashboard responsiveness. Most of the stakeholders were happy to wait 30 seconds more when they looked at their dashboards, knowing that they had the most up-to-date data possible. Operations needed to be more agile in their decisions and actions, so having fresh data was very important for them. To date, members of the Operations team remain the most active users of Tableau at Orfium and have been active participants in other data initiatives across the company.
The reception of these initial dashboards was amazing. The stakeholders could derive value and make smarter decisions faster, so the BI team gained confidence and trust. However, the BI team was still mainly serving the Operations department (with some requests completed for Clients and Corporate insights) but was starting to get many requests from Finance, Products, and other departments. We began to add additional BI Analysts to serve these needs. However, this was just the beginning of the creation of a larger team that could serve more customers more effectively, as we also began improving internal tech features and utilizing external solutions for ready-made software.
We had many questions to clear up:
Where to store our data, how to transform them, who is responsible for these transformations, who is responsible for the ready and delivered data points, who has access and how do they get it, where do we make our analyses, how do data move around platforms and tools, how do our data customers discover our work?
Months and months of discussions between departments on all these questions lead to a series of decisions and commitments about our strategic data plans.
Where we stand now is still a transition from the previous step, as we decided to take a giant step forward, by embracing the Data Mesh Initiative. We’ll have the chance to talk about some of the terms and combinations of software that we’re about to mention in future blog posts, but we can run through the basics right now.
Our company is growing very quickly and, given the fact that we prefer being Data-(insert cliche buzzword here), the needs and requests for BI and Data analysis are growing at double the speed.
The increase in the number of BI Analysts was inevitable with the increasing requests and addition of new departments in the company that needed answers for their data questions.
By hiring more BI Analysts, we split our workforce between our two main Data customers, and thus created two BI Squads.
One is focused on finance and external client requests. We named it the Corporate squad, and it consists of a BI Manager and 2 BI Analysts. This is the team that prepares the monthly Board meeting presentation materials (P&L, Balance Sheets), and the dashboards shared with our external customers so that we can use data to demonstrate the impact of our work on their revenue and so that they get a better understanding of their performance on YouTube. This squad also undertakes many urgent ad-hoc requests on a monthly basis. This squad has a zero tolerance policy for mistakes and usually works on a monthly revision/request cycle.
The second squad is more focused on analyzing, and evaluating the performance and usage of our internal products, and connecting that info with the performance of our Operations teams, which generate the largest portion of our revenue. This squad, which happens to work from two different time zones, again consists of a BI Manager and 2 BI Analysts, and has more frequent deadlines, as new features come up very fast and need evaluation. The nature of data and continuous evolution of the data model results in less robust data.
In the meantime, we had already realized that we had to bulletproof our infrastructure and technical skills before scale gets to us. We decided to have some team members focused on delivering value by creating useful analyses, as described above, but we also reserved time and people who were more focused on paving the way for the rest of the analysts to be able to create more value, more efficiently.
We researched the community’s thoughts on this and we found the term Analytics Engineer, which seemed very close to what we were looking for. We thought this would be very important for the team and decided to go one step further and create a separate role that would be the equivalent of the Staff Engineer for software engineering teams. This role is more focused on setting the technical direction of the department, researching new technologies, consulting on the way projects should be driven, and enforcing best practices within the Analytics Chapter of the Data Unit. Quality, performance, and repeatability are the three core values that the code produced by this department should have.
We currently have a team of 8 people including the BI Director, two squads, each with one BI Manager and two BI Analysts, plus the Staff BI Analyst.
In terms of skillsets, we left python behind. Instead, we’re focusing more on writing reliable and performant SQL code and collaborating on git efficiently as a team. Our new toolkit is also more or less co-decided by the endorsement of a centralized data mesh, which is currently hosted by Snowflake. Nothing is being hosted/processed locally anymore, we develop data pipelines using SQL, apply them to our dev/staging/production environments through dbt and orchestrate the scheduling and data freshness using Airflow. We are the owners of our own Data Product, which is Orfium’s BI layer. It is a schema in Orfium’s production database where we store our fresh, quality, and documented data resulting from our processes. This set of tables connects data from other teams’ data products (internal products, external reports, data science results) and creates interoperating tables. These tables are the base for all our Tableau Dashboards, and help other teams use curated data without having to reinvent the wheel of the Orfium data model on their own again. Our Data product and our Tableau sites with all of our dashboards are fully documented and enriched with metadata so that our data discovery tool Select Star allows stakeholders to search and find all aspects of our work.
Data Mesh was a big bet for Orfium and we will continue to build on it. The principles are applied and we are in the process of onboarding all departments on the initiative to be able to take advantage of the outcomes to the fullest extent. When this hard process is completed, all teams will enjoy the centralized data and the interoperability that derives from it, the Domain-Driven Data ownership, ensuring the agreed levels of quality on data, and it will help Orfium become more data-powered.
In addition to the obvious outcomes of applying the Data Mesh principles in a company, we believe that we need to follow up with two more major bets.
We decided to initiate, propose and promote Data Culture in Orfium. This is a very big project and is so deep that all employees need to get out of their comfort zones to achieve it. We need to change the way we work, to start planting data seeds very early in all our projects, products, initiatives, and working behavior so that we can eventually enjoy the results later on. This initiative will come with a Manifesto, which is being actively written and soon will be published. It will require commitment and follow-up on the principles proposed so that we achieve our vision.
Self-Service Analytics is also one of the Principles that Data Mesh is based on, and we decided to move forward emphatically with this too. Data will be generally accessible on Snowflake by everyone, but Data Analysis requires data literacy, SQL chops, and infrastructure that can host large amounts of data in an analysis. We decided to use Metabase as the proxy and facilitator for Self-Service Analytics. It provides the infrastructure by analyzing the data server-side, and not locally, and its query builder for creating questions is an excellent tool to create no-code analyses. Surely, it is not as customizable as SQL, but it will cover 85% of business users’ needs with superior usability for non-technical users.
This leaves us with data literacy and consultancy. For this, we have set up a library of best practices, examples, tutorials, and courses explaining how to handle business questions, analyses, limitations of tools, etc. At Orfium we always want to take a step further though, and we have been working to formulate a new role that will provide in-depth consultancy on data issues. This role will act as a general family doctor, who you know personally and trust, and will handle all incoming requests on data problems. Even if the data doctor cannot directly help you, they can direct you to a more suitable “doctor”, a set of more specialized experts, each one in their data sector (Infrastructure, SQL, Data Visualization, Analysis Requirement, you name it).
What a journey this has been over the last 3-4 years for BI in Orfium! We have gone through a lot, from not having official Business Intelligence to a BI team that has plans, adds value for the organization and inspires all teams to embrace the data-driven lifestyle. We’ve done a great job so far, and we have great plans for the future too.
It’s a long way to the top, if you want to rock and roll, ACDC

“Cookies” are small files that include information that a website (in particular, the web server) saves at the computer/tablet/mobile phone of a user, in order to enable retrieval of this information each time the user visits the website, thus offering to the user services relevant to it. An illustrative example of such information is the preferences of the user when visiting a website, which are identified by the way that the user uses the website (for example, by electing specific “buttons”, searches, advertisements etc.).
Cookies are regulated by the e-privacy directive 2002/58/EC as amended by the Directive 2009/136/EC (which was incorporated to the Greek Legislation by virtue of the Law 3471/2006), as is explicitly stated at the Regulation (EU) 2016/679 (General Data Protection Regulation), in particular at the recital no. 173. According to the legislation in force, i.e. the Law 3471/2016 (art. 4 para. 5 of said Law as amended by art. 170 of the Law 4070/2012): “The instalment of ‘cookies’ is permitted only with the consent of the user and under the condition of previous receipt by him/her of adequate information.”
For this reason and during the first visit of the user to the website https://orfium.com/ pop-up windows appear in order to enable the visiting user to grant his/her consent regarding the installment of cookies that are specifically mentioned and are non-functional cookies that aim at improving the products and services that appear at the Website as cookies used for statistical analysis regarding the number of visitors at the webpage and the number of pages viewed without direct identification of the user, advertising cookies concerning the collection of information for internet advertisement purposes, the advertisements being included in some general categories or fields of interest of the user through the examination of the websites that he/she browses and the links to other website that he uses, as well as the electronic messages that the user opens and the links that he uses from them by choosing advertisements only on the basis of data which do not permit the direct identification of the user.Specific categories of “cookies” have been assessed by Article 29 Working Party as technical – functional cookies; these cookies are necessary for connection to the website or the provision of the internet service. For these categories of cookies the Law does not require previous consent.
These are the following (see also WP29* Opinion 4/2012):
You can delete all cookies that are installed at your computer, as well as to alter the settings of the various browsers in order to prevent the installation of cookies. In this case, however, you may have to adjust by yourselves some preferences each time you visit a particular website, and some services may not be available.
In order to control and/or to delete the cookies according to your preferences, you can find all relevant details by consulting the following webpages:
http://ec.europa.eu/ipg/basics/legal/cookies/index_en.htm#section_2
You can easily accept or reject the cookies used by this website by choosing one of the following links
Any amendment to the present cookie policy will promptly appear to the Webpage
The present declaration is subject to periodic reviews and updates. In this case you can be informed by using the link ……………………. at the company’s website.
*WP29: It was founded by virtue of the article 29 of the Directive 95/46/EC on the protection of individuals with regard to the processing of personal data and on the free movement of such data. The Working Party had advisory status to the European Commission and acted independently. It was composed by a representative of the Data Protection Authority of each Member-State and assessed issues of particular importance or issues of special interest concerning the protection of personal data and falling within to the first pillar of the EU. Assessment of issues was performed either upon request of the European Commission or upon proposal by the members of the Working Party. The Working Party issued opinions and working documents. Upon the entering of the Regulation (EU) 2016/679 into force, the Working Party acts as European Data Protection Board.
At Orfium (hereafter as “Company” or “Orfium International Limited”), we are committed to maintain the highest standards of personal data protection and comply with pertinent privacy legislations. Our Privacy Policy presents our commitments to protecting the personal data processed after collected from any source. This privacy policy (“Policy”) describes how Hexacorp and its related companies collect, use and share personal information. The Company encourages you to read this Policy before using the Site or submitting any personal data. Your use of the Site signifies your agreement to our processing of personal data as described in this Policy and that you agree to all of the terms of this Policy.
The contact details of our Company are the following:
Address: 13-18 City Quay, Dublin 2, D02 ED70
Tel.: + (+30) 2109228995
E-mail: info@ofrium.com
Our Data Protection Officer will provide you with any information relevant to the processing activities of your personal data carried out by our Company and will assist you in exercising the rights awarded to you by the GDPR and outlined below.
The contact details of the Company’s Data Protection Officer are the following:
Advanced Quality Services Ltd.
Address: 1 Sarantaporou str, 145 65, Agios Stefanos Attikis, Greece
Tel.: + (+30) 2106216997
E-mail: dpo@orfium.com
What we collect
We get personal information about you in a range of ways
Cookies
We may log information using “cookies.” Cookies are small data files stored on your hard drive by a website. We may use both session Cookies (which expire once you close your web browser) and persistent Cookies (which stay on your computer until you delete them) to provide you with a more personal and interactive experience on our Site. This type of information is collected to make the Site more useful to you and to tailor the experience with us to meet your special interests and needs. For more details, you can access the Cookie Policy in this link.
Categories of data
The personal data we process on a case by case basis is:
Purpose of Processing
The reasons we process your data are on occasion to contact you in order to answer your questions and requests, to evaluate your resume, to sign contracts with you, to fulfill our contractual obligations to you, to fulfill the legal obligations arising from national and EU law.
Lawful basis for processing
In particular, the lawful basis for processing your data are as follows:
• Article 6 par. 1a GDPR you, the data subject has given consent to the processing of your personal data for one or more specific purposes;
On this basis we rely, for example, for processing your data after you have posed a question using our site or after you have filed a form or after an email you have sent us.
• Article 6 par. 1b GDPR processing is necessary for the performance of a contract to which you, the data subject, are counterparty or in order to take steps at the request of the data subject prior to entering into a contract;
On this basis we rely, for example, for processing your data during negotiations of any kind of contract or commercial agreements by disclosing your data when required by a third party recipient, Bank and Insurance Organization through which we can fulfill our contractual obligations to you.
• Article 6 par. 1c GDPR processing is necessary for compliance with a legal obligation to which the controller is subject.
On this basis, we rely to comply with our statutory obligations such as tax or insurance provisions, or obligations arising from the labor law.
• Article 9 par. 2b GDPR Processing is necessary for the purposes of carrying out the obligations and exercising specific rights of the controller or of the data subject in the field of employment and social security and social protection law in so far as it is authorised by Union or Member State law or a collective agreement pursuant to Member State law providing for appropriate safeguards for the fundamental rights and the interests of the data subject.
On this basis we rely, for example, for processing your data during our fulfillment to our contractual obligations to you.
Τhe period for which your personal data will be stored
Hexacorp retains your personal data for as long as the processing purpose persists, and after its expiration, we lawfully maintain your personal data when it is necessary to comply with a legal obligation under ΕU or national law (for example, Labor, Tax Insurance and Administrative Law) as well as in the case where the maintenance is necessary for the foundation, exercise or support of the legal claims of our company.
What are your rights
Right of Access
You have the right to receive a) confirmation regarding the processing of your data, and b) a copy of your personal data.
Right to rectification
You have the right to obtain from Hexacorp the rectification of inaccurate personal data concerning you, or ask to have incomplete personal data completed, when they are inaccurate.
Right to erasure
You have the right to obtain from Hexacorp the erasure of personal data concerning you, if you no longer wish to have such data processed and if there is no legitimate reason for us to own it as a controller.
In particular, this right shall be exercised when the lawful basis for processing is your consent and you withdraw it, so the data should be deleted if there is no other lawful basis for processing, when your personal data are no longer necessary in relation to the purposes for which they were collected or otherwise processed or unlawfully processed or if you object to the processing and there are no compelling and legitimate reasons for processing.
It should be noted, however, that this is not an absolute right, as the further retention of personal data by Hexacorp is lawful when necessary for reasons such as compliance with a legal obligation of the Organization or the foundation, exercise or support of legal claims.
Right to restriction of processing
As an alternative to the right to erasure and the right to object, you have the right to request that we process your data only in specific cases.
When do you have this right?
When:
The exercise of this right may be combined with the right to rectification and the right to object.
Specifically,
a) If you request the rectification of your inaccurate data, you may request a restriction of processing for as long as Hexacorp examines the rectification request,
b) If you request the right to objection, you may request at the same time the limitation of the processing for as long as Hexacorp examines the counterclaim.
Right to data portability
You have the right to receive your personal data that has been processed by Hexacorp as a controller in a structured, commonly used and machine readable format (for example XML, JSON, CSV, etc.). You also have the right to ask Hexacorp to transmit this data to another processor without any objection
The right to portability can only be exercised by you when all of the following conditions are fulfilled :
Right of objection
You have the right to oppose, at any time and for reasons related to your particular situation, to the processing of personal data concerning you when the processing is based either on (a task performed in the public interest) or on (if Hexacorp has a legitimate interest), including profiling.
The Organization will be required to stop such processing unless it demonstrates imperative and lawful reasons for processing that override your interests, rights and freedoms, or for the foundation, exercise or support of legal claims.
Right to non-automated individual decision making including profiling
If Hexacorp needs to make a decision that produces legal effects for you based solely on automated processing the following apply :
You have the right to submit a Complaint to the Data Protection Authority
If you find that your personal data is being processed unlawfully or your personal data has been violated, provided that you have previously contacted the DPO for the matter and you have exercised your rights towards us, and you either did not receive a reply within one month (extending the deadline to two months in the case of a complex request) and either you believe that the answer you received from us is inadequate and your issue is not resolved, you can contact the Greek Data Protection Authority, Kifissias Avenue 1-3, PC 11523, Athens, email: complaints@dpa.gr, fax 2106475628. For more information see the Web Portal www.dpa.gr.
Changes To This Privacy Policy
We may change this privacy policy. If we make any changes, we will change the Last Updated date above.
Last Updated: 01/01/2019
This Content Provider Agreement (also referred to as the “Upload Agreement”) between You (“You” or “Your” or “The Content Provider”) and Hexacorp Ltd., a Delaware corporation (“Hexacorp Ltd.” or “The Platform” or “Orfium” or “Orfium.com” or “The Service Provider” or “Us” or “Our”) entered into as of the date You license Digital Media to Us by uploading them to The Platform (the “Effective Date”) is a contract and applies to the Digital Media, as defined below, uploaded by You to The Service, as defined below. This Content Provider Agreement operates in conjunction with The Platform’s Terms of Service applicable to The Service and available at http://orfium.com/terms-of-use/. In the event of any inconsistency between this Content Provider Agreement and the Terms of Service, the terms of this Content Provider Agreement shall govern but only to the extent to resolve the conflict. If You do not agree to the terms of this Content Provider Agreement and Our Terms of Service then do not license Your content to Us and do not upload content to The Platform.
Section 1. Definitions
Section 2. License
Section 3. Refusal of Service3.1 The Platform reserves the right to delete, move, refuse to accept, or edit any Digital Media uploaded by You that, in its sole discretion, (i) violates or may violate this Content Provider Agreement, (ii) violates or may violate the intellectual property rights of others, (iii) violates or may violate the privacy rights of others, (iv) violates or may violate any of The Platform’s policies (v) violates or may violate the terms of service of another platform or service that The Service Provider administers on Your behalf or (vi) is deemed unacceptable in The Platform’s sole discretion. The Platform also reserves the right to refuse providing individual services for certain Uploaded Content. The Platform shall have the right, but not the obligation, to correct any errors or omissions in any Digital Media as it sees fit. Digital Media deemed unacceptable by The Platform are typically of low quality and/or low resolution.
Section 4. Royalties
Section 5. Derivative Works (Remixes)
Section 6. Third Party Rights
Section 7. Your Warranties7.1 By uploading or otherwise providing a Digital Media, You warrant that a) You are authorized to enter into this Agreement; b) You have the capacity and the authority to grant Us the rights granted by You to Us herein; c) each Digital Media asset uploaded by You is original and does not include sampled material unless You have obtained a license permitting the use of such sampled material; d) You are the original composer of all music and lyrics contained in the Digital Media, or You have licensed the rights to such music and lyrics from the original composer(s) and/or the copyright proprietor(s) of the original musical composition(s) from which such music and lyrics are derived; e) no Digital Media submitted by You will violate any law, or violate or infringe on the rights of any person, including contractual rights, copyrights, intellectual property rights, publicity and privacy rights or unfair competition, and no consent, license or permission is necessary or shall be required by You or any third party in connection with the transactions contemplated by this Content Provider Agreement; f) You are under no disability, restriction or prohibition with respect to Your right to execute this Content Provider Agreement, either on Your own behalf or on behalf of each member of Your group; g) in keeping with Section 2 and Section 4 of this Content Provider Agreement, The Platform will not be required to make any payments of any nature to anyone other than You, including all persons whose performances or ideas are contained on the Digital Media, its producer(s), publisher(s) or author(s) (including their rights societies) and any union, guild or affiliated trust fund. In addition to any other available remedies, if You breach this paragraph The Platform may immediately terminate this Content Provider Agreement and/or, if applicable, cancel and/or rescind any other arrangement between You and The Platform without any refund to You. You further agree to forfeit any royalties earned by You in connection with Your misconduct; i) In certain situations a PRO may require that You provide them with notice if You are granting public performance rights to another party. If You have an agreement with a PRO that includes such a provision, You are responsible for providing such notice to the PRO. As a result, You may wish to contact Your PRO to determine if You are able to enter into a license with The Service.
Section 8. Indemnity
Section 9. Modification and Termination
Section 10. Nondisclosure
Section 11. Arbitration and Agreement to Waive a Right to Jury Trial and Class Action11.1 You agree that ALL claims or disputes You have against The Platform must be resolved exclusively through binding arbitration, and You agree to waive Your right to jury trial and to participate in class actions. This agreement to arbitrate is intended to be broadly interpreted and covers all controversies, disputes, and claims. You agree that any arbitration under this agreement will take place on an individual basis. Class arbitrations and class actions are not permitted. You agree that any arbitration will be initiated by You through an established alternative dispute resolution (“ADR”) provider mutually agreed upon by the parties. The ADR provider and the parties must comply with the following rules: (a) the arbitration shall be conducted by telephone, online, and/or be solely based on written submissions, the specific manner shall be chosen by the party initiating the arbitration; (b) the arbitration shall not involve any personal appearance by the parties or witnesses unless otherwise mutually agreed upon by the parties, and in any such case, must take place in Los Angeles, California; (c) any judgment on the award rendered by the arbitrator must initially be entered into a state or federal court of law located in Los Angeles County, California. All claims You bring against The Platform must be resolved in accordance with this Legal Dispute Section. All claims filed or brought contrary to the Legal Dispute Section shall be considered improperly filed. Should You file a claim contrary to the Legal Dispute Section, The Platform may recover attorney’s fees and costs up to $2,000, provided that The Platform has notified You in writing of the improperly filed claim, and You have failed to promptly withdraw the claim.
Section 12. Miscellaneous
YOU EXPRESSLY ACKNOWLEDGE THAT YOU HAVE, IN ADDITION TO THIS CONTENT PROVIDER AGREEMENT READ AND AGREED TO THE TERMS OF SERVICE AND UNDERSTAND THE RIGHTS, OBLIGATIONS, TERMS AND CONDITIONS SET FORTH HEREIN. BY UPLOADING DIGITAL MEDIA TO THE PLATFORM AND/OR USE OF THE SERVICE, YOU EXPRESSLY CONSENT TO BE BOUND BY THE TERMS AND CONDITIONS HEREIN, AS APPLICABLE, AND GRANT HEXACORP LTD. THE RIGHTS SET FORTH HEREIN.
Save valuable time and resources finding and using licensed content and managing and reporting on your music cue sheet and production metadata with Soundmouse’s suite of broadcaster solutions.
Soundmouse by Orfium has become the global standard to receive, manage and report music cue sheets. It simplifies and automates the music cue sheet process, reducing manual input and saving you huge amounts of time and money.
Silvermouse by Orfium is the secure, modular online system to manage the workflow of production-related metadata to support broadcasters in streamlining data flows to support efficiency, compliance and diversity data monitoring initiatives.
MusicBox by Orfium is a cloud-based media library designed to manage and streamline the workflow of sourcing and using licensed music in any audiovisual production by broadcast media organizations.








Soundmouse is the trusted partner for broadcasters across the globe for music cue sheet automation, providing timely and comprehensive reporting to collecting societies and rights owners. The cloud-based platform connects all music industry stakeholders who can create, process, share, analyze and report music usage data in audiovisual productions in a streamlined and efficient way.
Soundmouse’s fingerprinting technology was developed at Cambridge University to meet the unique challenges of reporting of music copyrights and today, is established as the industry’s leading solution.
It holds more than 100 million unique tracks in its reference database and receives in excess of one million new recordings every week directly from record labels, production houses and individual artists and composers.
Find and use licensed content with ease.
MusicBox is a cloud-based media library designed to manage and streamline the workflow of sourcing and using licensed music in any audiovisual production by broadcast media organizations.
Its wide range of purposefully designed features allow music contributors to search for high quality licensed music, complete with metadata from a vast database of commercially released tracks and music libraries.
Looking for a particular track or type of music content? You can quickly run a rights clearance process and download and share the music tracks with your production teams.
Silvermouse is created for the collection, management and delivery of production metadata for both linear and non-linear productions.
Customizable: Silvermouse is highly customizable and enables broadcasters to streamline and securely collect, create, edit and report production metadata across all data categories.
Collaborative: It’s easy for broadcasters to collaborate with external partners with features such as comments, approvals, and form assignments.
Compliance: Designed to protect individuals’ anonymity, it’s GDPR compliant and adheres to broadcasters’ strict security policies,
My department is thrilled now that everything happens seamlessly with minimal manual effort. Soundmouse has truly simplified everyone’s life – there’s no more guesswork involved, which has saved us hundreds of man-hours in the past year.
Music is being used in more and more places including UGC platforms, fitness apps, video games, and OTT platforms, yet businesses are struggling to clear rights and access licensed music with ease.
With Orfium, get a comprehensive music rights picture that allows you to quickly and easily know which catalogs are cleared under your licenses. If you would like to make specific songs available, Orfium can help you identify the correct rights owners for both the sound recordings and compositional works for targeted and efficient licensing initiatives.




Access the full music rights picture. Find, use and report on licensed music with ease.
Understand what your existing license covers
With MusicHub, feel confident that the music you’re using is cleared for use. If you have a license in place, Orfium will provide clarity on which recordings or compositions are cleared under it.
Source and license the music you want to use
If you have a track you’d like to use but isn’t covered under your existing licenses, Orfium can help identify the correct rights owners so you can access the songs you need quickly and easily.
Get the reports you need in the format you need them
Meet rights holder reporting obligations in industry standard formats. Produce periodic usage reports for both rights holder distributions and to enable repertoire claiming.
Reconcile usage claims from rights holders
Orfium will validate and reconcile response files in industry formats including DDEX, CCID and CDM including running back-claim and technical discrepancy choreography.
Get notified about DSP payment release and claim disputes
Orfium provides dispute reporting to inform DSP payment release information and provides rights holders with notifications to allow claim disputes to be resolved.